[ad_1]
Introduction
Banking companies are accelerating their modernization effort and hard work to promptly develop and deliver prime-notch electronic encounters for their prospects. To accomplish the ideal achievable purchaser experience, choices have to have to be manufactured at the edge where by clients interact. It is important to accessibility affiliated information to make choices. Traversing the bank’s back again-finish methods, these as mainframes, from the digital encounter layer is not an alternative if the purpose is to supply the customers the ideal electronic encounter. Consequently, for producing selections quick devoid of a lot latency, associated facts really should be accessible nearer to the purchaser knowledge layer.
Fortunately, over the past couple of yrs, the information processing architecture has progressed from ETL-centric facts processing to serious-time or in close proximity to real-time streaming details processing architecture. These kinds of patterns as modify data seize (CDC) and command question responsibility segregation (CQRS) have evolved with architecture models like Lambda and Kappa. Though both equally architecture types have been extensively applied to carry information to the edge and method, about a interval of time facts architects and designers have adopted Kappa architecture over Lambda architecture for true-time processing of knowledge. Combining the architecture type with progress in event streaming, Kappa architecture is getting traction in purchaser-centric industries. This has considerably aided them to improve client knowledge, and, primarily for massive banking companies, it is aiding them to remain competitive with FinTech, which has already aggressively adopted celebration-pushed information streaming architecture to travel their digital (only) practical experience.
In this article, we explore the two architectural models (Lambda and Kappa) for knowledge processing at the edge and explain an example of true-existence implementation of Kappa Architecture in a retail banking customer encounter circumstance.
Lambda and Kappa Architecture
Equally the Lambda and Kappa architecture styles were being designed to guidance large facts analytics in processing and handling a significant quantity of info at a large velocity.
Lambda architecture, at first produced by Nathan Marz, addresses the troubles of the simultaneous knowledge processing prerequisites in batch and actual-time modes by segregating the movement of information into two distinct paths within the sample:
- The cold route (or batch layer) performs batch processing of facts in its raw type to retail outlet in batch check out where by latency is not a important need.
- The scorching path (or pace layer) performs actual-time processing of the info at very low latency but with lesser accuracy.
The batch layer inserts knowledge into a serving layer which suppliers info in an indexed batch view for productive querying. The velocity layer updates the serving layer with the most modern info. The two of these paths converge at the analytics consumer purposes where by the client can choose to see the info possibly from the chilly route or hot route. Even though there are sizeable rewards of Lambda architecture in conditions of retaining the enter info unchanged and the ability to reprocess info when essential, it should really be acknowledged that in Lambda architecture information processing logic, transformation logic, etcetera., are duplicated at two destinations and get carried out working with two distinctive systems/frameworks — for illustration, Hadoop for batch processing and Storm for velocity processing of information. This helps make the implementation of this architecture become operationally advanced.
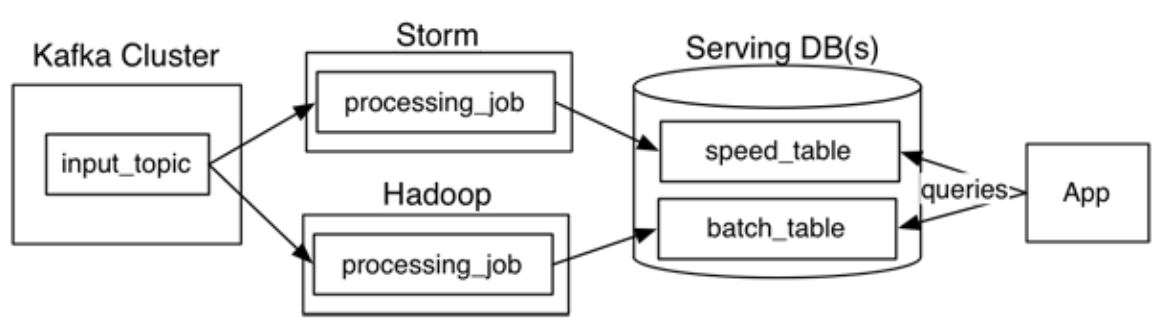
Fig 1: Lambda architecture
Kappa architecture, at first produced by Jay Kreps, proposed a one knowledge processing path utilizing a stream processing system that ingests occasions of information streams from details resources into a Kafka-like distributed fault-tolerant log. An party log is immutable and ordered. Any new celebration is appended to transform the existing point out of the function. As the info is persisted in the Kafka-like streaming technique, reprocessing of data is feasible by initiating a second occasion of a information stream processing career to course of action the very same enter facts and retail outlet it in a distinct table, if demanded for shopper software consumption.
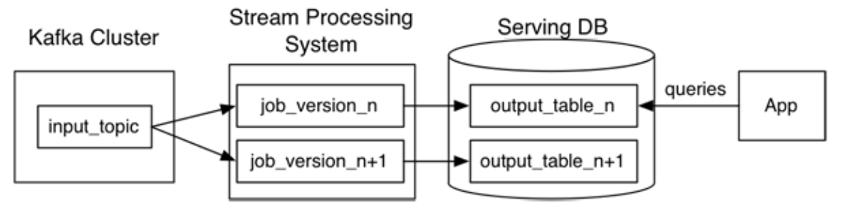
Fig. 1: Kappa architecture
Here’s a brief facet-by-aspect comparison of Lambda vs. Kappa architecture variations:
|
Architecture Style |
Pros |
Drawbacks |
|
Lambda |
|
|
|
Kappa |
|
|
Instance Implementation Situation of Kappa Architecture
The use scenario is as follows: Bringing selective SoR knowledge from the mainframe to the edge so the knowledge can be eaten by digital channels and lover devices. In this use situation, the main banking method is operating on numerous mainframes. The plan is to use domain-pushed design and style principles to section info products (along with relevant providers for consuming facts) and into domains like accounts, payments, agreements, and so forth. We leveraged the Kappa architecture for this use circumstance to construct a serious-time info cache forward of the system of records (SoR) to decrease “read” transaction pressure on the main banking process and guarantee the shopper receives constant general performance on the digital platform.
This architecture permits the agility to seize improvements to the client, account, agreements, and payment information in the core banking SoR and supply transformed facts in a constant and in close proximity to actual-time way, leveraging CDC (transform information capture) technology to the electronic entry layer. This architecture is implemented in a hybrid cloud natural environment to fulfill the pursuing requirements, in which main banking SoR resides on-premises and the electronic system is hosted in a general public cloud:
- Architecture need to offer genuine-time details stream processing
- Architecture ought to be really performant in terms of response occasions and throughput
- Knowledge solutions ought to be really readily available for company utilization
- All components of the architecture have to be horizontally scalable
- Expose APIs for channel applications to provide facts in authentic-time
The Architecture
The next diagram is an architectural overview of the remedy working with the Kappa pattern.
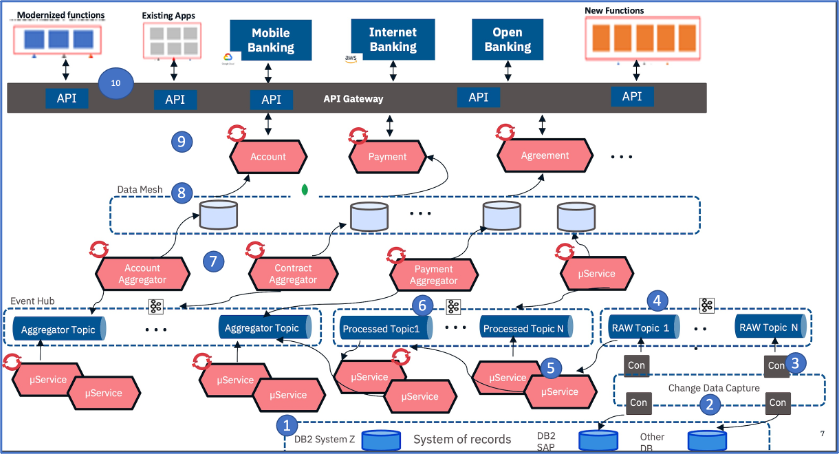
Fig 3: Kappa Architecture overview with CDC, knowledge pipeline and celebration streaming elements
The adhering to is the description of the architecture components enumerated in the over diagram:
- This layer signifies various main banking methods and their databases that contains accounts, clients, agreements, parties, deposits, and so on. These information are generally updated through a information-oriented middleware (Mom), set of procedure APIs, or ESB. For the sake of simplicity, this layer is not elaborated in the previously mentioned diagram.
- This component represents the transformed info seize (CDC) layer. CDC part in this layer identifies and captures improvements in the SoR database tables as and when the variations transpire. It supplies trusted, scalable, and minimal-latency replication of information amongst distinctive units hosted on-premises and on the cloud. There are numerous strategies to monitor variations in the database tables due to any new organization event or transactions. A person of the common methods is looking through transaction log files of any database for any new databases transactions of types build, delete and update. Other strategies include things like trigger-primarily based CDC and comparing deltas between tables.
- This layer runs personalized software regime parts built with CDC libraries. This customized element reads the CDC events and translates the functions to uncooked matters with the enable of an celebration streaming connector (Kafka Connect). Dependent on the different types of core process databases there could be various scenarios of these factors to get CDC facts and publish it into respective matters. In this precise consumer scenario, parts of these three levels were hosted at the on-prem details center.
- This layer hosts the total occasion streaming platform which is Kafka, and it is hosted in a public cloud. There are distinct techniques Kafka can be used in the cloud — employing its managed services software package from respective cloud distributors, applying Confluent Kafka®, or making use of Apache Kafka® set up and functioning on a cluster of VMs in the cloud. In this client state of affairs, it was a customized designed Apache Kafka clusters (for high performance and throughput) hosted on AWS community cloud. Primarily based on the diverse forms of functions captured from the backend programs, this layer will system several “raw subject areas.”
- This layer runs a set of microservices termed “unpacker services” as element of a details pipeline. These microservices do the validation of the construction of the data of the uncooked subject areas towards the formatted structure registered in the schema registry. In this specific implementation, this schema registry is Apache Avro®. Producers of the occasions also adhere to the same schema registry before publishing functions to the matters.
- Just after validation and unpacking of the data, these microservices link to unique subject areas recognized as “processed topics” (demonstrated as 6 in the diagram higher than) and publish processed information. Based on the intricate facts validation prerequisites and business enterprise rules checks, there could be one particular or two extra layers of matters concerning “raw topics” and “processed matters,” and consequently there could be an additional established of microservices as component of the “data pipeline” to publish and subscribe events from people subjects. There are a number of these types of “data pipelines” managing for facts events of the shopper, arrangement, accounts, and so forth., objects. For this shopper scenario, microservices of the data pipeline have been deployed in the Red Hat OpenShift® cluster hosted in the community cloud (AWS).
- Events from the “processed topic” are browse by an additional established of microservices termed “aggregator services” (revealed as 7 in the above diagram), which mixture some of the related details based mostly on information and time, arrangement id, and so on., and validate knowledge towards composition taken care of in schema registry. These solutions are also deployed in Pink Hat OpenShift® on the public cloud (AWS).
- Aggregator providers outlets info in a mesh of info cache shown as 8 in the diagram. This details mesh architecture includes NoSQL schemas with domain bounded facts all-around shopper, arrangement, account, and balances in which respective aggregated data are stored. This data mesh can be implemented by any personalized NoSQL document databases or managed cache solutions this kind of as Memcache, Redis, and many others., by general public cloud companies. For this unique shopper situation, it was carried out employing MongoDB.
- This layer had yet another set of microservices that are domain-centered. These microservices enable to accessibility (read) the knowledge from facts cache and expose as APIs for usage by exterior people these types of as web banking, mobile banking, and open banking programs. These companies are also deployed in Purple Hat OpenShift® on the community cloud (AWS)
- APIs are uncovered by means of an API Gateway provider of the cloud supplier (AWS).
Devices and parts explained over in 4 to 10 are all hosted on AWS general public cloud. Many this kind of data pipelines process business enterprise situations created from the method of information inside of the context of an personal domain (these types of as client, account, and payment) and offering it to the system of engagement by way of several “data ports” is essentially an tactic of shifting in the direction of decentralized “data mesh” architecture from a centralized occasion spine, of which Kappa architecture is the fundamental foundation.
This hybrid cloud implementation of Kappa architecture appreciably minimizes the load on the company middleware and main system database. Facts functions uncovered as APIs also offer the ability to a bank, their associates, and other ecosystem companies in developing additional options and revolutionary applications.
References
- Questioning the Lambda Architecture by Jay Kreps
- Overview of CDC Replications, IBM documentation
- Data Mesh Ideas and Sensible Architecture by Zhamak Dheghani
- Lambda or Kappa? by Anand Rao
Acknowledgments
The adhering to are the architects who were being concerned in defining the original architecture model that inevitably progressed to this in depth applied Kappa architecture.
- Harish Bharti, Distinguished Engineer, IBM
- Rakesh Shinde, Distinguished Engineer, IBM
[ad_2]