[ad_1]
Chaos Mesh is a cloud-native chaos engineering system that orchestrates chaos experiments on Kubernetes environments. It will allow you to exam the resilience of your system by simulating complications such as community faults, file technique faults, and Pod faults. Just after each individual chaos experiment, you can evaluation the testing final results by examining the logs.
But this tactic is neither immediate nor economical. Therefore, I determined to establish a every day reporting system that would automatically assess logs and deliver reviews. This way, it is uncomplicated to examine the logs and discover the issues.
In this report, I will introduce how chaos engineering allows us boost our system resilience and why we need to have a day by day reporting method to complement Chaos Mesh. I’ll also give you some insights about how to establish a every day reporting technique, as well as the challenges I encountered in the course of the system and how I preset them.
What Is Chaos Mesh and How Does It Aid Us?
Chaos Mesh is a chaos engineering system that orchestrates faults in Kubernetes. With Chaos Mesh, we can conveniently simulate extraordinary circumstances in our small business and exam regardless of whether our process continues to be intact.
At my enterprise, we merge Chaos Mesh with our DevOps system to deliver a one-click CI/CD approach. Every time a developer submits a piece of code, it triggers the CI/CD method. In this procedure, the technique builds the code and performs device assessments and a SonarQube quality verify. It then deals the picture and releases it to Kubernetes. At the conclusion of the working day, our each day reporting procedure pulls the latest visuals of each and every project and performs chaos engineering on them.
The simulation does not require any application code change Chaos Mesh takes treatment of the tough do the job. It injects all types of actual physical node failures into the system, these kinds of as community latency, community reduction, and community duplication. It also injects Kubernetes failures, these types of as Pod or container faults. These faults might expose vulnerabilities in our application code or the technique architecture. When the loopholes surface area, we can deal with them in advance of they can do authentic hurt in manufacturing.
Spotting these vulnerabilities isn’t effortless on the other hand, the logs will have to be thoroughly examine and analyzed. This can be a tricky work for both the software developer and the Kubernetes professional. The developer may not function properly with Kubernetes a Kubernetes professional, on the other hand, could not realize the software logic.
This is wherever the Chaos Mesh day by day reporting procedure will come in. Following the every day chaos experiments, the reporting method collects logs, attracts a plot, and offers a web UI for examining the doable loopholes in the system.
In the adhering to sections, I’ll demonstrate how to operate Chaos Mesh on Kubernetes, how to crank out day-to-day studies, and how to construct a net software for day by day reporting. You are going to also see an case in point of how the program allows out in our output.
Operate Chaos Mesh on Kubernetes
Chaos Mesh is developed for Kubernetes, which is 1 of the essential reasons why it can enable users to inject faults into the file process, Pod, or network for certain purposes.
In earlier files, Chaos Mesh available two means to promptly deploy a virtual Kubernetes cluster on your device: form and minikube. Frequently, it only normally takes a one particular-line command to deploy a Kubernetes cluster as well as install Chaos Mesh, but commencing Kubernetes clusters domestically influences network-linked fault kinds.
If you use the presented script to deploy a Kubernetes cluster utilizing variety, then all the Kubernetes nodes are virtual devices (VMs). This provides issue when you pull the graphic offline. To address this situation, you can deploy the Kubernetes cluster on multiple actual physical devices alternatively, with just about every bodily machine acting as a worker node. To expedite the picture pulling process, you can use the docker load command to load the required impression in progress. Aside from the two problems higher than, you can install kubectl and Helm by next the documentation.
In advance of you set up Chaos Mesh, you want to 1st produce CRD resources:
git clone https://github.com/pingcap/chaos-mesh.gitcd chaos-mesh# Build CRD methodskubectl use -f manifests/
Following that, set up Chaos Mesh applying Helm:
# For Helm 2.Xhelm set up chaos-mesh/chaos-mesh –name=chaos-mesh –namespace=chaos-testing# For Helm 3.Xhelm put in chaos-mesh chaos-mesh/chaos-mesh –namespace=chaos-tests
To run a chaos experiment, you have to define the experiment in YAML documents and use kubectl implement to start it. In the pursuing case in point, I create a chaos experiment utilizing PodChaos to simulate a Pod fail:
apiVersion: chaos-mesh.org/v1alpha1
sort: PodChaos
metadata:
name: pod-failure-instance
namespace: chaos-screening
spec:
action: pod-failure
method: just one
benefit: ''
period: '30s'
selector:
namespaces:
- chaos-demo-1
labelSelectors:
'app.kubernetes.io/component': 'tikv'
scheduler:
cron: '@each and every 2m'Let’s implement the experiment:
kubectl utilize -f podfail.yaml
Crank out a Everyday Report
For demonstration reasons, in this article, I run all the chaos experiments on TiDB, an open up-source, distributed SQL databases. To make everyday reviews, you have to have to collect logs, filter glitches and warnings, attract a plot, and then output a PDF.
Acquire Logs
Generally, when you operate chaos experiments on TiDB clusters, quite a few faults are returned. To accumulate individuals mistake logs, run the kubectl logs command:
kubectl logs -n tidb-take a look at -–since=24h >> tidb.log All logs produced in the past 24 hours of the precise Pod in the tidb-check namespace are saved to the tidb.log file.
Filter Glitches and Warnings
In this step, you have to filter error messages and warning messages from the logs. There are two alternatives:
- Use text-processing applications, these kinds of as
awk. This involves a proficient knowledge of Linux/Unix commands. - Compose a script. If you’re not acquainted with Linux/Unix commands, this is the much better option.
The extracted mistake and warning messages will be utilised in the up coming action for more assessment.
Attract a Plot
For plotting, I suggest gnuplot, a Linux command-line graphing utility. In the illustration under, I imported the pressure check benefits and produced a line graph to exhibit how queries per 2nd (QPS) are influenced when a specific Pod gets unavailable. Due to the fact the chaos experiment was executed periodically, the amount of QPS exhibited a pattern: it would drop abruptly and then speedily return to standard.
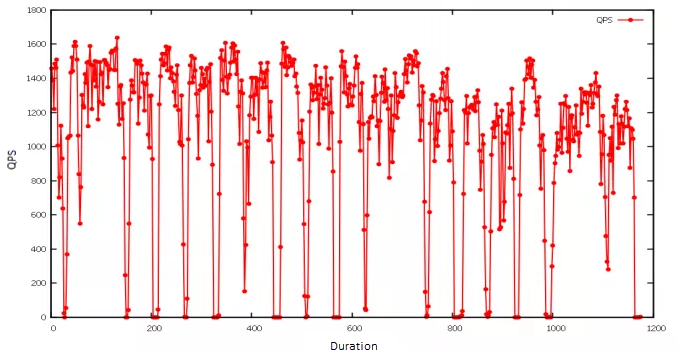
QPS line graph
Produce the Report in PDF
Presently, there is no accessible API for creating Chaos Mesh studies or examining success. My recommendation is to create the report in PDF format so it will be readable on unique browsers. In my situation, I use gopdf, a aid library that makes it possible for consumers to build PDF files. It also lets you insert images or attract tables, which satisfies the requires of a chaos engineering report.
The very last stage is to basically run the entire technique at a scheduled time just about every working day. My choice is crond, a command-line utility that executes cron work opportunities in the history, to execute the commands early every single early morning. So, when I start off operate, there is a each day report ready for me.
Develop a Web Application for Day-to-day Reporting
I want to make the report additional readable and obtainable. Isn’t it nicer if you can check out studies on a internet software? At initial, I required to include a backend API and a databases to retail outlet all report knowledge. It appears relevant, but it may well be too significantly get the job done because all I want is to know which report involves further more troubleshooting. The correct information and facts is shown in the file name, for example: report-2021-07-09-poor.pdf. Consequently, the reporting system’s workload and complexity are significantly reduced.
Still, it is vital to boost the backend interfaces as well as enrich the report articles. But for now, a every day, workable reporting method is just great.
In my situation, I utilized Vue.js to scaffold the world-wide-web application employing a UI library antd. Right after that, I current the web page written content by conserving the quickly generated report to the static resources folder static. This enables the web application to examine the static reviews and then render them to the front finish website page. For particulars, check out out Use antd in vue-cli 3.
Down below is an illustration of a world-wide-web application that I formulated for every day reporting. The crimson card indicates that I really should test the screening report mainly because exceptions are thrown following jogging chaos experiments.

Internet application for daily reporting
Clicking the card will open the report, as revealed beneath. I utilized pdf.jsto render the PDF.
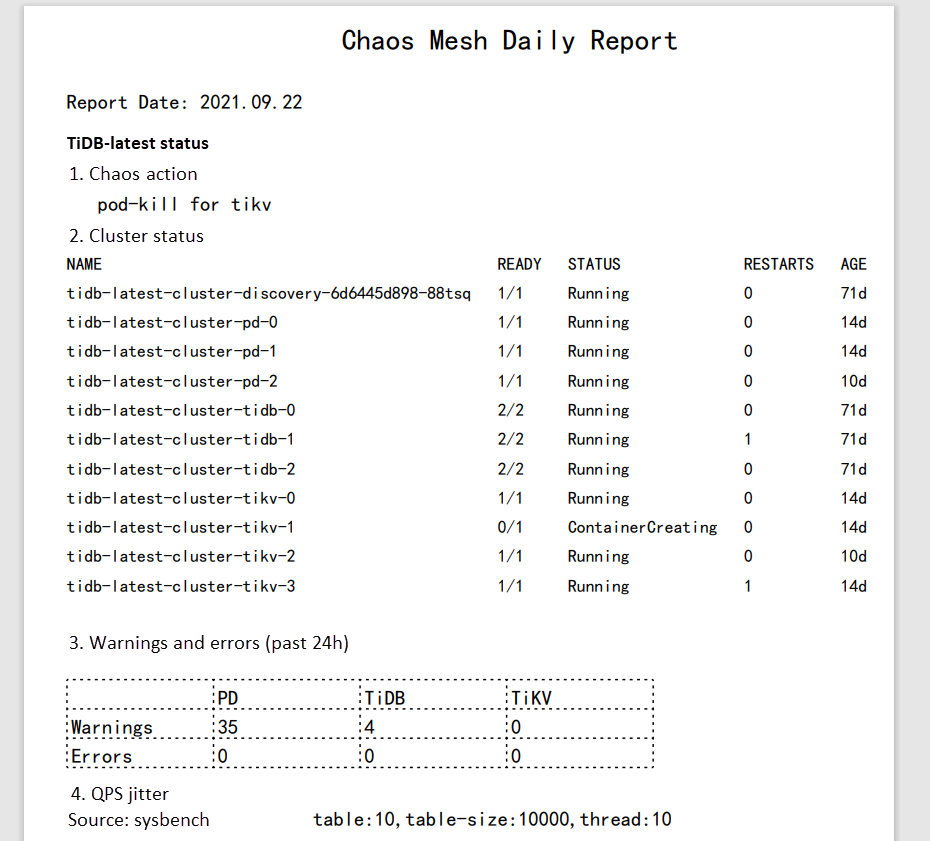
Every day report in PDF
Summary
The Chaos Mesh every day reporting procedure has been are living in our organization for 4 months. Thankfully, the procedure has served us find out bugs for many jobs in serious conditions. For illustration, one time we injected a community replicate and network reduction failure into an application and set the duplication and deal reduction ratio at a high amount. As a outcome, the application achieved unpredicted situations for the duration of concept parsing and ask for dispatch. A deadly mistake was returned, and the plan abnormally exited. With the help of the day by day report, we immediately received the plot and logs for the certain mistake. We utilised that details to effortlessly track down the bring about of the exception, and we set the process vulnerability.
Chaos Mesh enables you to simulate faults that most cloud-indigenous purposes might come upon. In this short article, I produced a PodChaos experiment and noticed that QPS in the TiDB cluster was affected when the Pod turned unavailable. After examining the logs, I can boost the robustness and higher availability of the process. I crafted a world-wide-web application to deliver everyday studies for troubleshooting and debugging. You can also customize the reports to meet your have specifications.
[ad_2]