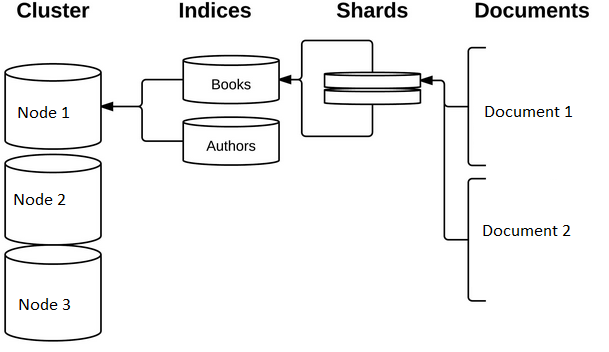
Cluster:
A cluster is a group of one or more servers that together contains entire data. It provides the facility to index and search across all nodes. A cluster can have any number of nodes. A cluster have a unique name. Default name of the cluster is elasticsearch (all in lower-case letters). Default cluster name can be changed.
Note: If multiple nodes joined through a network then they automatically forms a cluster named elasticsearch.
Node:
Each server in a cluster is known as node and used to store data. Each node will participate in the indexing and searching functionalities of the cluster. Every node of a cluster can handle the client’s HTTP request. When a client’s request comes to the Elasticsearch cluster, a node will receive the request and then it will be responsible to complete the request. Every node in the cluster knows the state of every other node in the cluster. The node which receive the client’s request can forward the request to another node in the cluster through transport layer.
Like cluster, every node also has a unique name that is Universally Unique Identifier, also known as a UUID. Default node name can also be changed.
Note: In terms of relational databases, a node represents the DB Instance.
Master Node:
Master node is the node that is responsible for updating the state of the cluster, creating, updating and deleting of an index and deciding which node will contain which shards etc.
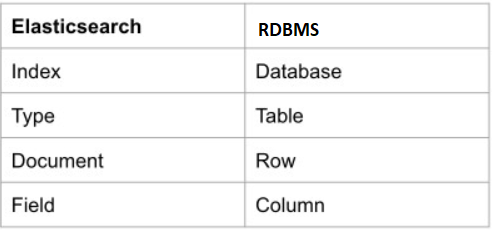
Document:
A document represents one unit of data that can be indexed. It will be in JSON format. Elasticsearch will assign a unique ID to every document.
Note: In terms of RDBMS, a document represents the row in the table.
Index (Indices):
An index is way of organizing the document data. It is a group or collection of documents with similar characteristics.
Note: In terms of RDBMS, an index represents a Database or schema.
Mapping Type:
A type represents the logical group of documents with in index.
Note: In terms of RDBMS, a type represents a table.
Shards:
A shard represents the subset of index documents, that is logical partition of index. An index can have multiple shards.
Replicas:
Replicas represents the duplicate data presents across the nodes to maintain the high availability.
REST API:
Rest API are used by client to interact with the Elasticsearch.
NRT(Near-Real-Time):
Elasticsearch is one of the near-real-time search platforms. When a document is indexed, it becomes searchable within 1 second.
Relation between RDBMS and Elasticsearch terms: